-
Pl
chevron_right
Erlang Solutions: GraphQL interfaces in MongooseIM 6.0
news.movim.eu / PlanetJabber • 19 December 2022 • 9 minutes
MongooseIM is a robust, scalable and highly extensible instant messaging server. Recent releases have improved its configurability and opened new use cases, and the latest version 6.0 continues that trend. By introducing the brand new GraphQL API, we made MongooseIM much easier to integrate with external web services. The entry barrier is also lower than ever because of the automatically generated API documentation, interactive web UI, and the new Command Line Interface (CLI), that can execute predefined GraphQL operations for you, providing help when necessary. The latest changes are exciting, but to fully understand and appreciate them, let’s start with summarizing the state of the API and CLI in the previous version 5.1.
MongooseIM 5.1: API and CLI before the changes
The primary interface exposed by MongooseIM is the c2s (client-to-server) listener using XMPP – an open, battle-proven, well-adopted and extensible protocol with an active community behind it. While we believe that XMPP is an excellent choice for an interface to which end user devices connect, there are important use cases when other interfaces might be useful:
- An administrator can use the Command Line Interface ( CLI ) to manage the server and its extensions.
- A user device or a consumer-facing Web UI can use the REST API to perform operations that don’t require an XMPP connection.
- An administrative web service can use the REST API to manage the server and its extensions.
The diagram below shows the architecture of the interfaces that allow such operations:
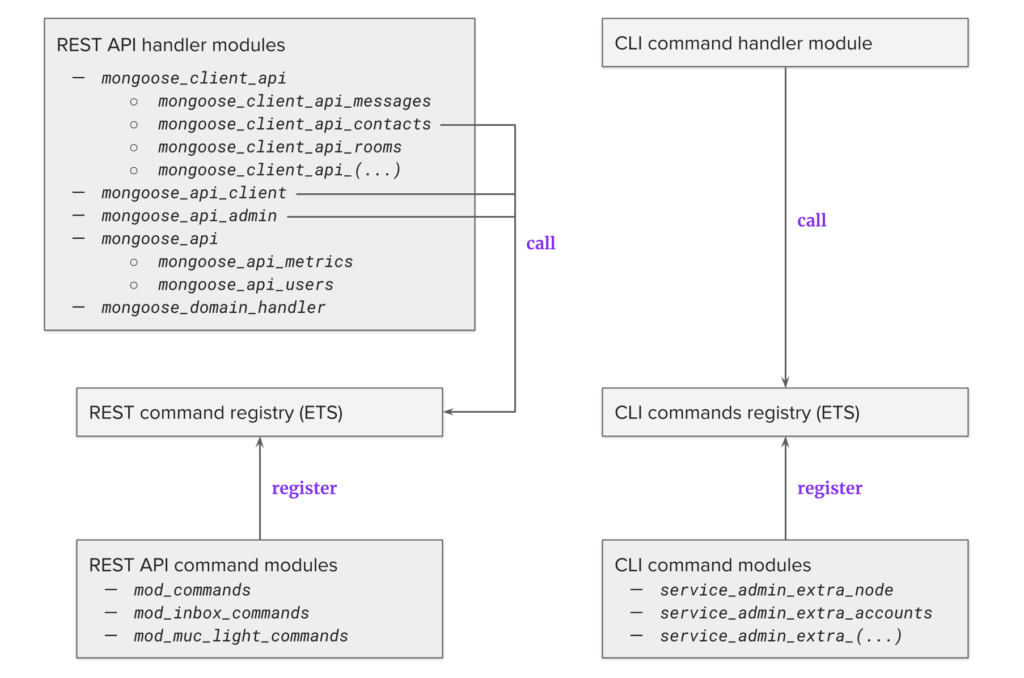
The REST API is pictured on the left. The top block contains a list of HTTP handlers that need to be configured in the TOML configuration file,
mongooseim.tom
l
.
There are two handler types here:
-
Admin API
:
mongoose_api_admin, mongoose_api, mongoose_domain_handler -
User (client) API
:
mongoose_client_api, mongoose_api_client
The module names can be confusing. This is because the API was developed in a few iterations over the years, and the design patterns have changed a few times. By default, the Client and Admin APIs are enabled for different HTTP listeners. This setup is recommended because the administrative API should be protected from being accessed by regular users. Some of them, like
mongoose_client_api
, contain several command categories that can be enabled individually. The handler modules are responsible for executing these commands, and they are doing so by either directly calling internal modules, or by executing commands registered in the REST command registry. The latter is more organized, but command registration is quite complicated. As a result, only some handler modules are doing so (as shown in the diagram). To register the appropriate commands in the REST command registry, you would configure the respective extensions modules, e.g.
mod_commands
contains most of the commands, but if you wanted to manage chat rooms, you’d need to enable
mod_muc_light_commands
.
The CLI is shown on the right side of the diagram. The command handler is a module that gets called by Erlang RPC, which executes the commands registered in the CLI commands registry. To have them registered, you need to configure specific command categories in
service_admin_extra
.
It is evident from the diagram that REST API logic is completely disjoint from the CLI one. Command registries are separate, and although they both use the Erlang ETS tables to store the commands, they have very different command formats. As a result, if the same command is available in both interfaces, it would need to be implemented twice. Code reuse is possible, but not enforced, so most often the logic is not shared. The configuration is also very different for both.
Finally, and most importantly, many commands are implemented only for the Client REST API, only for the Admin REST API, or only for the CLI. We addressed all of these issues in the new release, so let’s see what the improved architecture looks like.
MongooseIM 6.0: Introducing GraphQL
The architecture of the new GraphQL interfaces is shown in the following diagram.
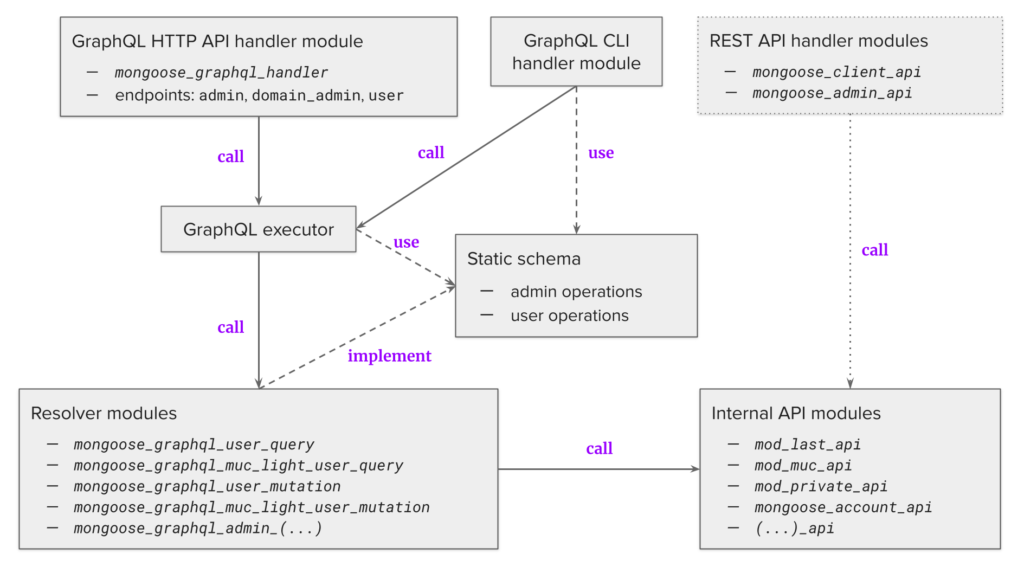
The GraphQL API is handled by
mongoose_graphql_handler
, which is configured for an
HTTP listener
, and can be enabled for three different endpoints: Admin, Domain Admin and User.
Let’s see how each of them is configured by default:
The password-protected Admin endpoint is listening at 127.0.0.1:5551.
[[listen.http]]
ip_address = "127.0.0.1"
port = 5551
[[listen.http.handlers.mongoose_graphql_handler]]
host = "localhost"
path = "/api/graphql"
schema_endpoint = "admin"
username = "admin"
password = "secret"
The Domain Admin is a new level between Admin and User, and is meant to be used by administrators of single XMPP domains. Domain credentials are configured by the global administrator with the Admin interface, and the domain administrator has to provide them when accessing the Domain Admin interface.
[[listen.http]]
ip_address = "0.0.0.0"
port = 5541
[[listen.http.handlers.mongoose_graphql_handler]]
host = "_"
path = "/api/graphql"
schema_endpoint = "domain_admin"
Finally, the User endpoint requires providing the credentials of a specific XMPP user, and allows user-specific commands to be executed.
[[listen.http]]
ip_address = "0.0.0.0"
port = 5561
[[listen.http.handlers.mongoose_graphql_handler]]
host = "_"
path = "/api/graphql"
schema_endpoint = "user"
The handlers are calling the GraphQL executor, which performs operations declared statically in two schemas: Admin and User. The Domain Admin uses the Admin schema, but there are special @protected directives which guarantee that a domain administrator can only execute these operations for their own domain. The commands are implemented as three different GraphQL operation types:
- Queries for requesting information from the server, e.g. a user can request archived messages.
- Mutations for performing an action on the server, e.g. a user can send a message.
- Subscriptions for requesting a stream of updates from the server, e.g. a user can subscribe for incoming messages.
Operation logic is defined in the resolver modules, which in turn call the internal API modules to execute the logic. This way there can be no ad-hoc calls to arbitrary internal logic in the resolver modules. There is no command registry required anymore, and a special
@use directive
in the schema ensures that
modules
and
services
required by each executed command are enabled.
The GraphQL-based CLI handler module exposes the GraphQL commands from the Admin schema. Each command uses an automatically generated GraphQL query. This means that the same administrative commands are present in the HTTP GraphQL API and in the CLI. The old CLI is deprecated, and will be removed soon. The REST API will be still available for some time, but it will be phased out as well. In version 6.0, it was reworked to use the internal API modules, and it no longer requires the REST command registry. Thanks to the static schema, we could use SpectaQL to automatically generate the documentation for the Admin and User APIs. Another feature is the GraphiQL UI, which lets you experiment with the API in your browser. You can use browser plugins such as Altair as well.
CLI and API in numbers
All the operations offered by the old CLI and API are now available in the new GraphQL interfaces. We also added many new commands:
| Legacy CLI | Legacy REST API | GraphQL API and CLI | |
| Admin commands | 56 | 32 | 114 |
| User commands | 16 | 55 |
Starting with the Admin (and Domain Admin) interfaces, we can compare the functionality offered by the legacy CLI, legacy REST API and the new GraphQL API. The diagram below shows the number of commands offered by each interface:
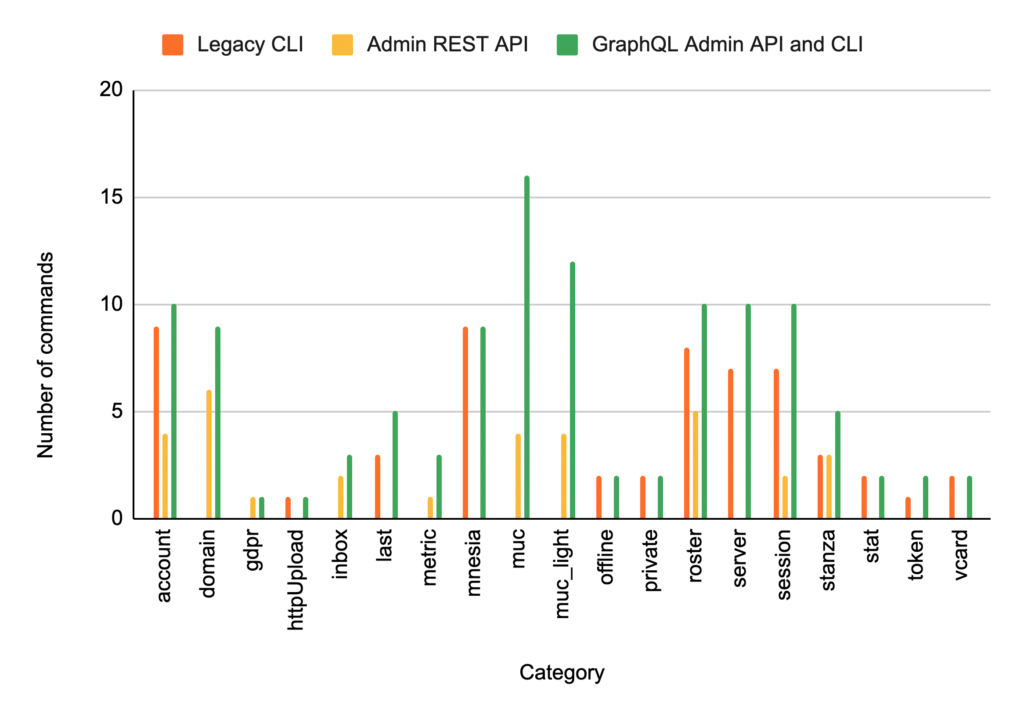
For example, the domain category was unavailable with the legacy CLI, and the REST API offered four commands allowing you to add, remove, enable and disable dynamic XMPP domains. The new GraphQL commands offer them all, but also add two new ones, responsible for setting and removing domain-admin passwords. For some categories, like
muc
and
muc_light
(both implementing multi-user chat) we offer many more commands than before, allowing you to configure and use MongooseIM in new ways. The comparison looks similar for the User API:
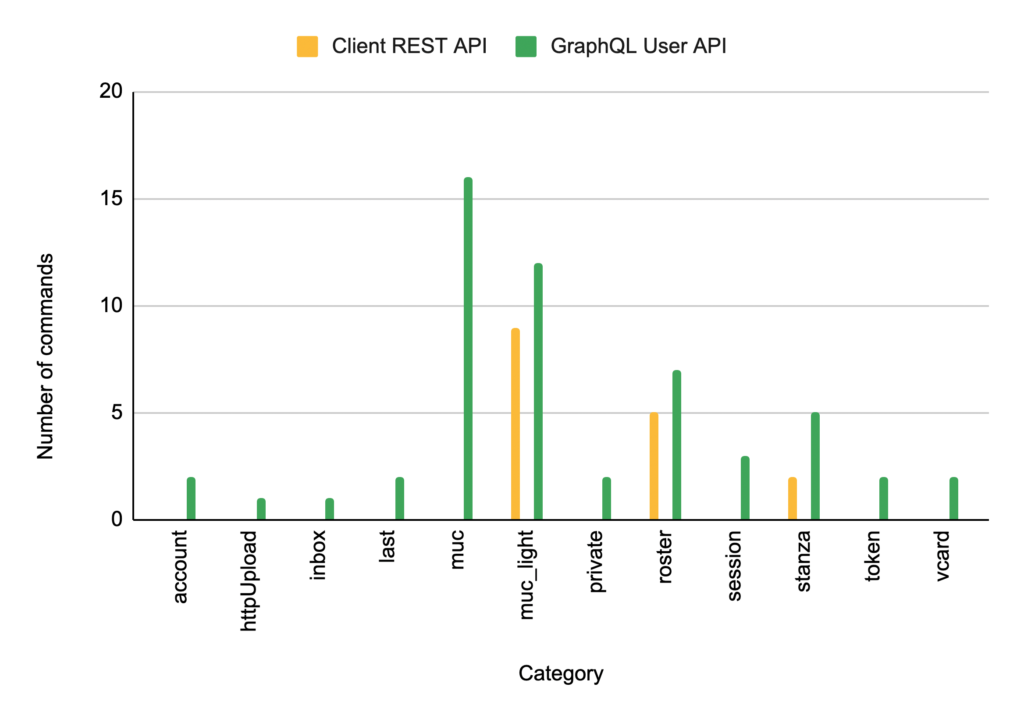
CLI and API in action
The command line interface is the easiest one to use. To start, you only need to call the
mongooseimctl
command.
Let’s assume that we need to add a new user, but we don’t know how to do so:
$ mongooseimctl
Usage: mongooseimctl [category] command [arguments]
Most MongooseIM commands are grouped into the following categories:
account Account management
domain Dynamic domain management
gdpr Personal data management according to GDPR
httpUpload Generating upload/download URLs for the files
inbox Inbox bin flushing
last Last activity management
metric Browse metrics
mnesia Mnesia internal database management
muc MUC room management
muc_light MUC Light room management
offline Deleting old Offline messages
private User private storage management
roster User roster/contacts management
server Server info and management
session User session management
stanza Sending stanzas and querying MAM
stat Server statistics
token OAUTH user token management
vcard vCard management
To list the commands in a particular category:
mongooseimctl category
(...)
The account category is the one we are interested in.
$ mongooseimctl account
Usage: mongooseimctl account command arguments
The following commands are available in the category 'account':
banUser Ban an account: kick sessions and set a random password
changeUserPassword Change the password of a user
checkPassword Check if a password is correct
checkPasswordHash Check if a password hash is correct (allowed methods: md5, sha)
checkUser Check if a user exists
countUsers Get number of users per domain
listUsers List users per domain
registerUser Register a user. Username will be generated when skipped
removeUser Remove the user's account along with all the associated personal data
To list the arguments for a particular command:
mongooseimctl account command --help
Now we know that the command is called
registerUser
.
$ mongooseimctl account registerUser --help
Usage: mongooseimctl account registerUser arguments
Each argument has the format: --name value
Available arguments are listed below with the corresponding GraphQL types:
domain DomainName!
password String!
username UserName
Scalar values do not need quoting unless they contain special characters or spaces.
Complex input types are passed as JSON maps or lists, depending on the type.
When a type is followed by '!', the corresponding argument is required.
The arguments are listed with their GraphQL types. Both
DomainName
and
UserName
are essentially strings, but there are more complex types as well. To learn more about a particular type, use our
online documentation
.
Knowing the arguments, you can create the user now:
$ mongooseimctl account registerUser --username alice --domain localhost --password mysecret
{
"data" : {
"account" : {
"registerUser" : {
"message" : "User alice@localhost successfully registered",
"jid" : "alice@localhost"
}
}
}
}
Now, let’s explore one more interface – the web UI provided by GraphiQL . Assuming that you have the GraphQL handlers set up with the default configuration, you can open http://localhost:5551/api/graphql in your browser, and enter the following query:
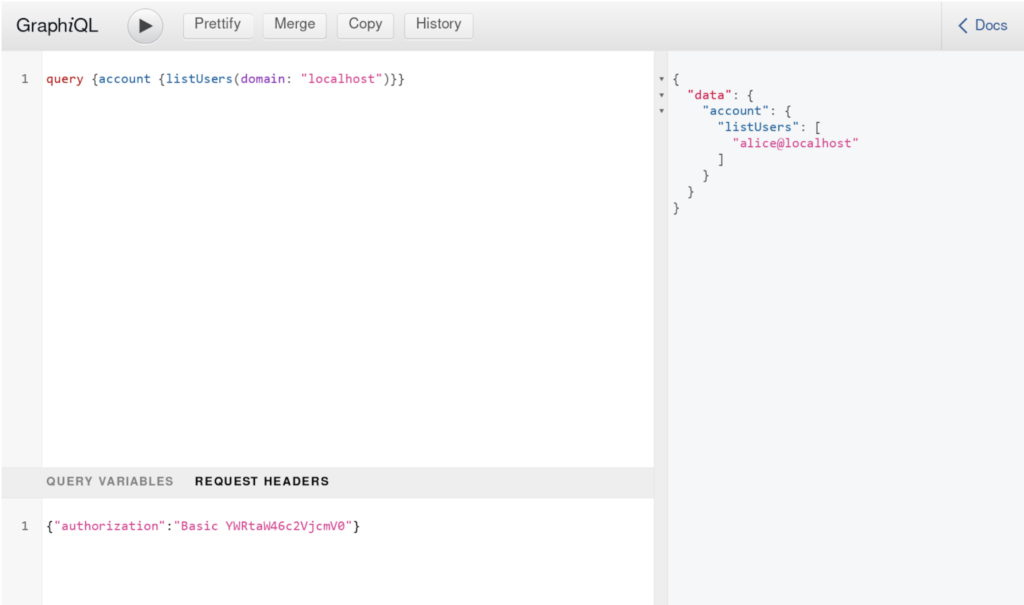
You need to provide the authorization header as well. This one uses the default credentials, which you should of course change in your production environment. On the right you can see the results including the newly created user. You can use the Docs tab to learn more about a particular command.
More than just the new API
We have barely scratched the surface of the new features available in MongooseIM 6.0. Apart from the ones presented, these are some of the other improvements you can see in our latest release:
- Dynamic domain removal is now asynchronous and incremental, which is useful if there is a lot of data to clean up.
- Better pagination support for Inbox .
- Internal rework of hooks and handlers.
- Various improvements and fixes – see the Release Notes for details. We merged almost 200 pull requests since the last release.
We are now working on more exciting features, so stay tuned, because we will have more news soon.
The post GraphQL interfaces in MongooseIM 6.0 appeared first on Erlang Solutions .